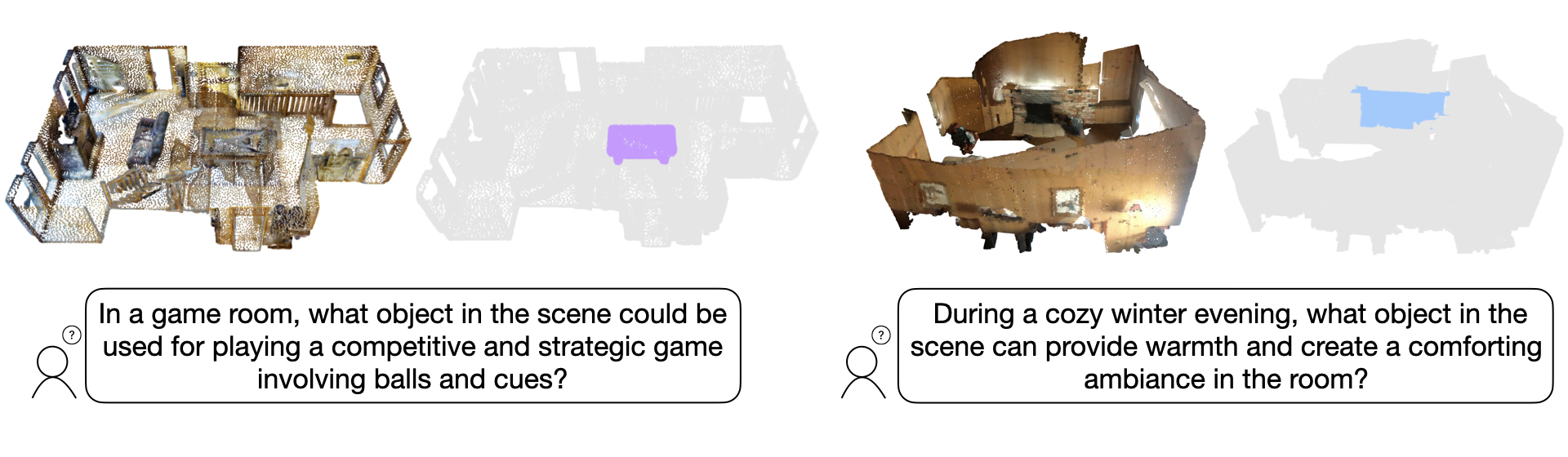
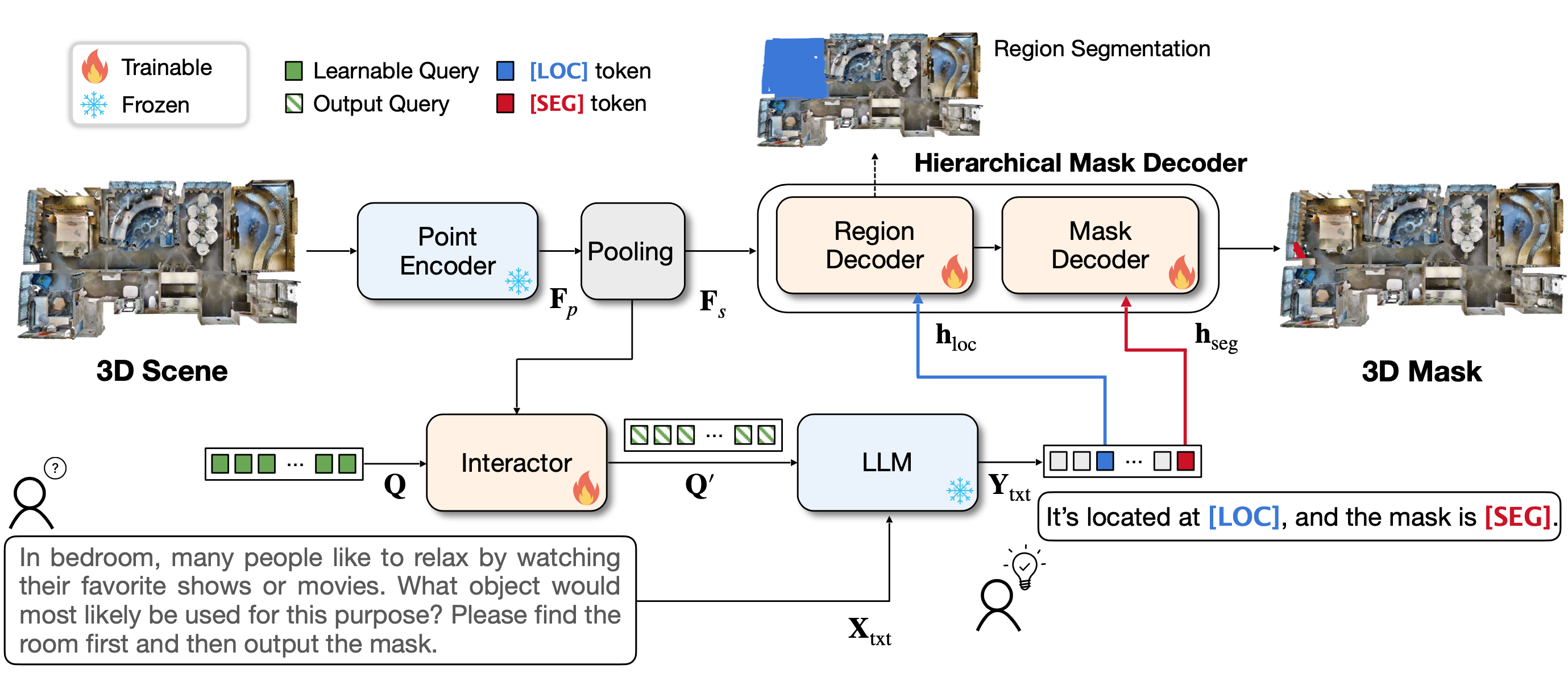
How do LMMs handle 3D segmentation?
Recent advancements in multimodal large language models (LLMs) have shown their potential in various domains, especially concept reasoning. Despite these developments, applications in understanding 3D environments remain limited. They primarily offer textual or numerical outputs without the capability to generate dense, informative segmentation masks.
This paper introduces Reason3D, a novel LLM designed for comprehensive 3D understanding. Reason3D takes point cloud data and text prompts as input to produce textual responses and segmentation masks, facilitating advanced tasks like 3D reasoning segmentation, hierarchical searching, express referring, and question answering with detailed mask outputs.